אימות קולי
01/03/2022

המידע שהמכשיר הסלולרי שלנו יכול להכיל הוא מגוון ולפעמים גם אישי מאוד, ולכן ברור לנו שאימות בעזרת ביומטריה נחוץ לשמירה על הפרטיות שלנו. אז השיטות לאימות באמצעות טביעת אצבע או זיהוי תווי הפנים כבר מוכרות, אבל מה בדבר טביעת הקול שלנו?
פרסומת
ביומטריה קולית היא טכנולוגיה המבוססת על זיהוי דפוסי קול כדי לאמת זהות של אנשים. מכיוון שלכל אדם קיימים מאפייני דיבור אקוסטיים ופונטיים הייחודיים רק לו [1], אפשר להבחין בין אנשים על פי השוני הקולי ביניהם בלבד. כמו שלא קיימים שני אנשים בעלי אותה טביעת אצבע, כך גם אין שני אנשים עם אותה חתימה קולית. בזכות השונות הקולית אנו יכולים לייצר מערכות מבוססות דיבור אשר יהיו מסוגלות להבחין בין דוברים שונים [2].
בשנים האחרונות נכנסו מערכות בעלות ממשק משתמש קולי לשגרת חיינו – אנחנו מתקשרים בעזרת פקודות קוליות עם מערכות הרכב, נותנים פקודות קוליות ל"עוזרים וירטואליים” (סירי, אלכסה) ואפילו נעשה שימוש בקול שלנו באפליקציות פיננסיות ובבנקים על מנת להזדהות ולבצע פעולות רגישות [3]. ככל שגדלה יכולתם של המכשירים האישיים שלנו להכיל מידע רב יותר ולבצע פעולות רגישות יותר, כך נעשה ברור יותר שאפליקציות אלה חייבות להיות מוגנות בעזרת ביומטריה קולית.
למעשה, אותן מערכות מנסות לפתור את בעיית אימות הדובר. בהינתן קטע דיבור, יש להחליט באופן אוטומטי מי הדובר בקטע על סמך הסיגנל הקולי בלבד. להבדיל ממשימת זיהוי הדיבור שבה נשאלת השאלה “מה נאמר?”, כאן נשאלת השאלה “מי אמר?”. זו אולי נשמעת כמו משימה קלה יותר, אבל בפועל מדובר במשימה לא פחות מורכבת.
אז אחרי שהתחלנו להבין מהן מערכות לאימות הדובר, נסביר כיצד מתכננים מערכת כזו וכיצד למידה עמוקה, שדיברנו עליה בפוסט קודם [4], משתלבת במערכות אלו.
בשלב הראשון מבצעים עיבוד של ההקלטה הקולית. המטרה בעיבוד הדיבור היא להשיג דרך נוחה ויעילה לייצוג המידע שנמצא בו. אות הדיבור הגולמי עצמו אינו מתאים לזיהוי הדובר כיוון שהוא רועש ומכיל מידע רב מאוד שאינו חיוני בהכרח לזיהוי הדובר, ולכן נדרש ייצוג אחר של האות, שיהיה כמה שיותר אינפורמטיבי וכמה שפחות רועש.
בפועל, לוקחים את ההקלטות הקוליות של מורשי הגישה ומבצעים להן תחילה ניקוי רעשים (רעשי רקע מן הסביבה) ולאחר מכן וקטוריזציה. אנו רוצים שהמערכת תהיה מסוגלת לזהות את הדובר בכל הקלטה (ללא תלות באורך המלל), ולכן בתהליך הווקטוריזציה אנו לוקחים את מקטע הקול ומזהים בו תכונות ומאפיינים אקוסטיים. התכונות יכולות להיות תדר הדיבור, קצב, טונציה, מנעד, לקויות וכו'. התכונות הללו אינן תלויות ב"מה" אנחנו אומרים, אלא ב"איך" אנחנו אומרים. לכן בחירה טובה ונכונה של המאפיינים תאפשר השגת תוצאות זיהוי טובות יותר תוך שימוש במערכות פשוטות יותר.
ישנם אלגוריתמים רבים לחילוץ מאפיינים הפועלים בשיטות שונות ומגוונות, ואחד הפופולריים שבהם הוא האלגוריתם [5] (MFCC (Mel Frequency Cepstrum Coefficient.
ננסה להסביר באופן אינטואיטיבי מה לוכד האלגוריתם בעזרת הקישור הבא [6]: הקשיבו לצלילים בתדר 300 ו-400 הרץ ודמיינו את הבדלי הגבהים ביניהם. כעת, עשו זאת שוב עבור צלילים בתדר 900 ו-1000 הרץ. המרחק הנתפס בין שני הצלילים הראשונים נדמה גדול יותר מהשניים האחרונים, אף שבפועל ההבדל ביניהם זהה (100 הרץ). הסיבה לכך טמונה בעובדה שלבני אדם קל בהרבה להבחין בשינויים קטנים בגובה הצליל בתדרים נמוכים, וזוהי בדיוק הייחודיות של אלגוריתם זה. האלגוריתם, כמו בני האדם, רגיש מאוד לשינויים בתדרים הנמוכים ולכן יכול לזהות שינויים קלים כאלו בהקלטה הקולית. עם זאת, בשונה מבני האדם, האלגוריתם רגיש הרבה יותר ומסוגל לזהות כמעט כל שינוי בגובה הצליל, ולכן הוא מצליח להבחין בשינויים הקלים ביותר בתדר ולתחום אותם, ומתייחס אליהם כאל תכונה ייחודית.
אז איך בעצם קשור האלגוריתם הזה ללמידה עמוקה? כאן נכנס לתמונה החלק ה"דקורטיבי" יותר של האלגוריתם. בזכות האופן שבו האלגוריתם עובד, אנחנו למעשה יכולים להציג עכשיו את ההקלטה הקולית כתמונה צבעונית מאוד, כמו התמונה שמופיעה להלן.
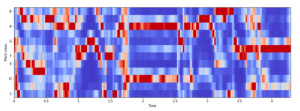
כך נראית המילה "כן" אחרי שהקלטתי אותה בעזרת המיקרופון של המחשב והפעלתי את אלגוריתם MFCC. אפשר לראות בתמונה את אוסף התכונות הקוליות שלי, גם אם לא ממש ברור לנו מה אנחנו רואים.
בעזרת תמונה זו, ועוד רבות אחרות, אנו יכולים עתה לאמן רשת נוירונים (שגם עליהן כבר כתבנו פוסט [7]) לזהות את הקול שלי בעזרת שיטות של למידה עמוקה. אלגוריתמים של למידה עמוקה מאפשרים לרשת נוירונים ללמוד כיצד "נראה" הקול שלי; התמונה מכילה את מרבית המידע אודות הקול שלי, וכך הרשת תהיה מסוגלת להבחין ביני ובין קול של אדם אחר. בהצגת ההקלטה הקולית כתמונה המייצגת את התכונות הווקאליות של הדובר, אנו יכולים לאמן רשתות עמוקות לבצע את תהליך אימות הדובר מהר יותר וביתר דיוק.
מערכות לאימות דוברים לא משמשות רק לצרכים אישיים, אלא גם יכולות לשמש בחקירות פליליות ויש להן מעמד משפטי בזיהוי חשודים [8]. עם זאת, חשוב להבין שמערכת כזו אינה מושלמת. בהחלט יש מקום לעבודת מחקר רבה ולשיפור הטכנולוגיה, אבל לא רחוק היום שבו נוכל להזדהות בקול.
עריכה: שיר רוזנבלום-מן
מקורות לקריאה נוספת:
[2] ספר מקיף אודות עולם הביומטריה:
Jain, Anil K., Patrick Flynn, and Arun A. Ross, eds. Handbook of biometrics. Springer Science & Business Media, 2007.
[3] כתבה על חברת הבנק שמזהה לקוחות על פי חתימת קולם
[4] פוסט על למידה עמוקה של מדע גדול, בקטנה
[5] מאמר בנושא השימוש באלגוריתם MFCC לצורך אימות וזיהוי דובר
[6] קישור לאתר שבו אפשר לחולל צלילים בהתאם לתדירות
[7] פוסט על רשתות נוירונים של מדע גדול, בקטנה
[8] קישור לכתבה על שימוש במערכת לזיהוי הדובר בבתי המשפט

דוקטור בתוכנית הבין-יחידתית למערכות אוטונומיות ורובוטיקה (TASP) בטכניון