קיבוץ לא מפוקח
13/10/2021

אוסף נתונים עשוי להכיל לעיתים נקודות מידע רבות, שאפשר לסווג לכמה קטגוריות. לדוגמה, קיבוץ אזורי משלוח דואר למספר מוקדים מרכזיים מאפשר לתת שירות יעיל יותר. בפוסט זה נדון בשיטת קיבוץ נתונים שנקראת K means Clustering, המאפשרת לסווג מספר רב של נתונים שאין לנו מידע מקדים עליהם, לקבוצות שמספרן נקבע מראש.
פלונית המדענית מעוניינת לשלוח לקראת החג חבילות מתנה גדולות לחבריה ולמשפחתה. פלונית נעזרת בחברת ההזנק "דואר 2.0", אשר הקצתה למשימת החלוקה כמה שליחים. מכיוון שהחבילות גדולות, כל שליח יכול לקחת רק חבילה אחת כל פעם. נניח לצורך הדוגמה כי מדובר בעשרה שליחים הנדרשים לחלק מאה חבילות. אפשר להקצות באופן אקראי לכל שליח עשר חבילות לחלוקה, אך אם ננקוט שיטה זאת, ייתכן שחלק מהשליחים יצטרכו לנסוע גם למטולה וגם לבאר שבע. בשיטה מעט חכמה יותר השליחים יחלקו ביניהם את החבילות שווה בשווה, עשר לכל אחד, לפי אזורי החלוקה שלהם, וכך יפחיתו את עומס העבודה. שיטת העבודה מניחה הנחה מקלה, וככל הנראה שגויה, שמכריה של פלונית מפוזרים באופן אחיד ברחבי הארץ. אך מה אם לפלונית יש 24 מכרים באזור קיבוץ בית קשת שבגליל התחתון, ורק קרוב משפחה אחד בקיבוץ יהל שבערבה? במקרה זה נרצה לחלק את העבודה בצורה לא שווה, אך הגיונית יותר מבחינת פריסה גיאוגרפית: כל שליח יתרכז באזור חלוקה מסוים, ויחלק את החבילות לנמענים המתגוררים הכי קרוב למרכז החלוקה. בדרך זו נוכל לקצר את מרחקי הנסיעה ולהקל על השליחים.
שיטה זו נקראת קיבוץ נתונים (באנגלית clustering), והיא דרך מקובלת לתיאור נקודות מידע רבות מתוך אוסף נתונים בעזרת כמה מקבצים. קיימות שיטות שונות לבצע קיבוץ נתונים שכזה, ורובן משתמשות בכלים סטטיסטיים מוכרים, ממוצע וסטיית תקן לדוגמה, או במידע מוקדם על אוסף הנתונים. קיבוץ כזה מאפשר לנו לנתח את המידע ולהסיק ממנו מסקנות [1].
לאחר שתיארנו בעזרת דוגמה מהו מקבץ, נתאר אלגוריתם שיכול לקבץ אוסף נקודות מידע גם כאשר לא ניתן שום מידע עליהן מלבד מיקומן במרחב או מרחקיהן זו מזו. השיטה נקראת K means, והיא מתבססת על חלוקת נקודות המידע למספר קבוע מראש של מרכזי נתונים (במקרה זה K אינו מסמל את המילה "קבוע", אלא מייצג מספר שלם הגדול מאפס) [2]. K הוא מספר שבוחר המשתמש, ולרוב הוא לרוב נקבע בניסוי וטעיה או מדרישות של המערכת. למשל – אם יש לי רק שלושה שליחים, אחלק את כל נקודות המסירה לשלוש קבוצות, וכך כל שליח יקבל את המקבץ המתאים.
כיצד עובד האלגוריתם? ראשית הוא קובע באקראי מיקום התחלתי למרכזי המקבצים, ולאחר מכן חוזר על מספר פעולות בסיסיות עד להתכנסות, כלומר עד הגעה לשלב שבו מתקיים תנאי כלשהו שנקבע מראש (תנאי עצירה). לאחר בחירת מיקום מרכזי המקבצים מחושב המרחק בין כל נקודה לבין כל מרכזי המקבצים, וכל נקודה משויכת למקבץ המתאים לה, זה שמרכזו הוא הקרוב ביותר לנקודה. כעת נרצה לבצע בחירה מושכלת יותר של מרכזי המקבצים, ולשם כך נחשב את המרכז של כל הנקודות השייכות לכל מקבץ. עתה נחלק שוב את הנקודות למקבצים, וייתכן כי חלק מנקודות המידע יעברו בין מקבצים. כך נמשיך שוב ושוב, עד שנגיע למצב המספק אותנו. תנאי עצירה יכול להיות למשל השלמת מספר קבוע מראש של חזרות על החישובים, או שלב שבו לא מחליפה שום נקודה את המקבץ המתאים לה ביותר. יש לשים לב שאלגוריתם זה פותר את הבעיה לפי התנאים ההתחלתיים, שנקבעו באקראי. ייתכן בהחלט שתנאי פתיחה שונים יביאו לתוצאה שונה.
האלגוריתם שייך למשפחת האלגוריתמים הבלתי מפוקחים (unsupervised), כלומר – איננו יודעים מה התיאור של כל נקודה; ידוע רק מיקומה היחסי ביחס לשאר הנקודות על מערכת צירים מסוימת. למעשה, כל שנדרש כדי להפעיל את האלגוריתם הוא האפשרות לתאר את המרחק בין נקודות בעזרת פונקציה מסוימת. שימוש נפוץ למדי של השיטה הוא למציאת קשר בין מספר רב של פריטים באוסף נתונים, וסיווגם לקבוצות שונות. נקודות המידע יכולות להיות שייכות למגוון תחומים, לדוגמה – תופעות לוואי של חיסון, מחירי דירות באזורים מסוימים ואף אטרקציות לטיולים ברחבי הארץ. אפשר לחלק את האזורים לנקודות מרכז כמו בדוגמה המתוארת לעיל [3], או להבחין בין עצמים בתמונה בעזרת סיווג של עוצמות צבע של פיקסלים [4]. הנקודות יכולות להיות נקודות עניין בתמונה, למשל נקודות השייכות לעצמים זהים בתמונות שונות (כתבנו על כך בעבר [5]), ואף נקודות השייכות לעצמים שונים בסריקה תלת-ממדית [6].
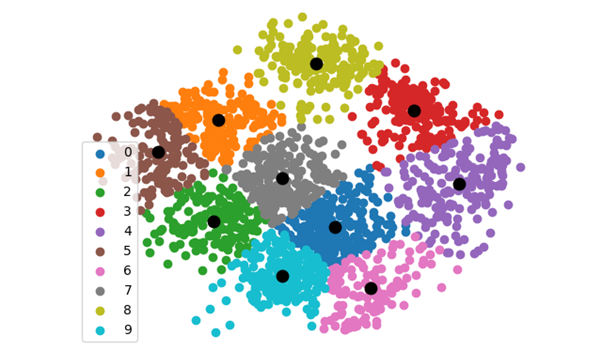
פיזור מרכזי מקבצים שחושבו בעזרת K means עבור 10=K ומידע מפוזר בצורה דו-ממדית

תמונה צבעונית ותיאורה בעזרת שלושה צבעים בלבד בעזרת זיהוי מקבצי הצבעים במרחב RGB. שיטה זו מאפשרת סימון עצמים בתמונה, כמו למשל בית המשחק, כלבת לברדור ומשחקי חצר נוספים.

תמונה צבעונית ותיאורה בעזרת שני צבעים בלבד בעזרת זיהוי מקבצי הצבעים במרחב RGB. ניתן לראות בבירור את ההפרדה בין הזמר (חנן בן ארי) לבין הרקע.
תיארנו בפוסט זה אלגוריתם בסיסי לסיווג נתונים באופן בלתי מפוקח (unsupervised). אלגוריתם זה שימושי ביותר לצורכי סיווג נתונים כאשר חסר לנו מידע על כל נתון, וידוע רק השוני היחסי בין נתון אחד למשנהו. דוגמאות לשימוש באלגוריתם זה הן סיווג מסמכים ומיילים לפי קבוצות, פתרון בעיית אופטימיזציה לביצוע משלוחים, זיהוי וסיווג התנהגות של לקוחות למניעת הונאות, התאמת מוצרים ללקוח על סמך העדפות של לקוחות דומים ועוד [7].
איור ותמונות: צבר דולב
ליווי מדעי: דוד קייסר
עריכה: סמדר רבן
מקורות והרחבות:
[1] הסבר על בעיית קיבוץ (clustering)
[2] הרצאה קצרה של Cyrill Stachniss בנושא K means clustering
[3] Ferrandez s., 2016, "Optimization of a truck-drone in tandem delivery network using k-means and genetic algorithm", Journal of Industrial Engineering and Management 9(2):374
[4] חלוקת תמונה למספר אזורים בעזרת אלגוריתם K means
[5] פוסט שלנו בנושא מציאת מאפיינים דומים בתמונות
[6] קיבוץ נקודות במודל תלת ממדי בעזרת K means
[7] מגוון שימושים לאלגוריתם K means

אלגוריתמאי וחוקר ראייה ממוחשבת וגיאומטריה חישובית, בוגר תואר ראשון ושני בהנדסת מכונות בטכניון. בימים אלו עוסק בפיתוח אלגוריתמים לרכבים אוטונומיים.