זיהוי קטלני
10/08/2020

לעיתים נדירות אנו כותבים על סרטים איכותיים וניסיוניים כגון זה, אך הפעם נחרוג ממנהגנו ונתמקד בסרט האיכות שהיה זמין בסינמטקים הקרובים לביתכם, הסרט "מהיר ועצבני: הובס ושואו". בסרט זה דוויין ג'ונסון וג'ייסון סטיית'האם מצילים את העולם (שוב) מנבלים גנריים המעוניינים להשמיד את העולם. בסרט...טוב, העלילה לא באמת רלוונטית, מדובר בסרט אקשן גנרי. אבל בסצנה אחת מתוך הסרט גיבורינו נדרשים לפתוח דלת בעזרת זיהוי פנים, לאחר שכיסחו לרעים את הצורה. הם עוברים אדם אדם ומנגחים את פניו במכשיר לזיהוי פרצופים. מה עומד מאחורי הטכנולוגיה הזאת? [1]
https://www.youtube.com/watch?v=WmYSA9yqqFg
במשימת זיהוי פנים (facial recognition) נדרשים לזהות פנים מתוך מאגר פנים קיימות. זאת אומרת שיש לנו מאגר פרצופים ותמונה של האדם המבוקש (סטגדיש) ונרצה לדעת מי האדם בתמונה מבין האנשים במאגר. נציין שמשימה זו שונה ממשימת איתור פנים (face detection) שבהינתן תמונה מזהה איפה יש בה פנים.
בעיית הזיהוי מזכירה בעיית קיטלוג (קלסיפיקציה) שבה נתונים לנו מספר קטגוריות של עצמים ביניהם נרצה להבדיל (למשל: כלב, חתול, ג'ירפה, אריה), ובהינתן תמונה צריך לזהות לאיזו קטגורייה היא שייכת. בניגוד לבעיית זיהוי, בבעית קיטלוג הקטגוריות האפשריות ידועות מראש ועבור כל קטגורייה יש המון דוגמאות (תמונות) ללמוד מהן. מצד שני, בבעייה זו מורשי הכניסה יכולים להשתנות לאורך הזמן, למשל הם יכולים להתווסף או לעזוב. לא סביר לאמן מערכת חדשה על כל שינוי כזה, בנוסף לכך שעבור כל פרצוף יש לנו רק מספר תמונות בודדות ללמוד מהן.
אחת הדרכים לזהות פנים היא באמצעות מערכת אינטליגנציה מלאכותית הנקראת faceNET. המערכת מקבלת תמונת פנים והופכת אותה לנקודה יחידה בעולם רב מימדי אחר (בעל עשרות או מאות מימדים), שבו המרחק בין נקודות שונות משקף את הדימיון בין הפנים בתמונות. כדי לזהות מי בתמונה, המערכת מוצאת את הפנים במאגר שהכי קרובות לפנים שאנחנו מחפשים באותו "עולם רב מימדי".
כיצד מלמדים את המערכת לאן להעביר את הנקודות כך שהמרחק ביניהן ישקף את הדמיון בפנים?
מערכות למידה עמוקה לומדות מפידבקים. שואלים אותן שאלות, וכאשר הן עונות לא נכון הן מקבלות "עונש" או פידבק שלילי, ובהתאם לפידבק הן לומדות איך להשתפר להבא.
כדי ללמד את המערכת לעשות עבודה טובה, אנחנו צריכים לקבוע דרך להעניש ולתגמל אותה בהתאם לביצועים שלה. לשם כך מגדירים פונקציית מחיר שנותנת ציון חיובי או שלילי לפי טיב ביצוע המשימה. כדי שהמערכת תצליח להבין במה להשתפר, הפידבק צריך להיות נקודתי (למשל, ציון לכל "שאלה קטנה" במקום ציון כללי על כל המבחן), כך שהמערכת תוכל "לדעת" באילו שאלות היא טעתה.
מתי נוכל להגיד שהמערכת עשתה עבודה טובה? הבעייתיות היא שממיקום נקודה של תמונה בודדת אי אפשר להסיק כלום לגבי טיב המערכת. מפני שלא יודעים לאילו תמונות אחרות התמונה קרובה. אם ניקח שתי תמונות נוכל למדוד את המרחק ביניהן, אבל מרחק הוא דבר יחסי. זה שהנקודות המייצגות שתי תמונות של אותו אדם קרובות, לא אומר שנזהה נכון, יתכן שתמונה של אדם שונה תהייה קרובה יותר.
מערכת faceNET משתמשת בפונקציית מחיר (נותנת ציון) הנקראת טריפל לוס. המערכת מחלקת את התמונות לשלשות: תמונה של אדם שרוצים לזהות (עוגן), תמונה נוספת של אותו אדם (תמונה נכונה), ותמונה של אדם שונה (תמונה שגוייה). המערכת צריכה להכריע באיזו מבין שתי האופציות (תמונה נכונה ושגויה) מופיע אדם זהה לעוגן. המערכת הופכת את שלושת התמונות לנקודות במרחב ומשווה בין המרחקים בין העוגן לתמונה הנכונה והשגויה. המערכת מנחשת שהתמונה הקרובה יותר לעוגן היא האדם הזהה. אם המערכת טעתה בהחלטה ובחרה בדוגמה השגויה, היא מקבלת פידבק שלילי ולומדת ממנו.
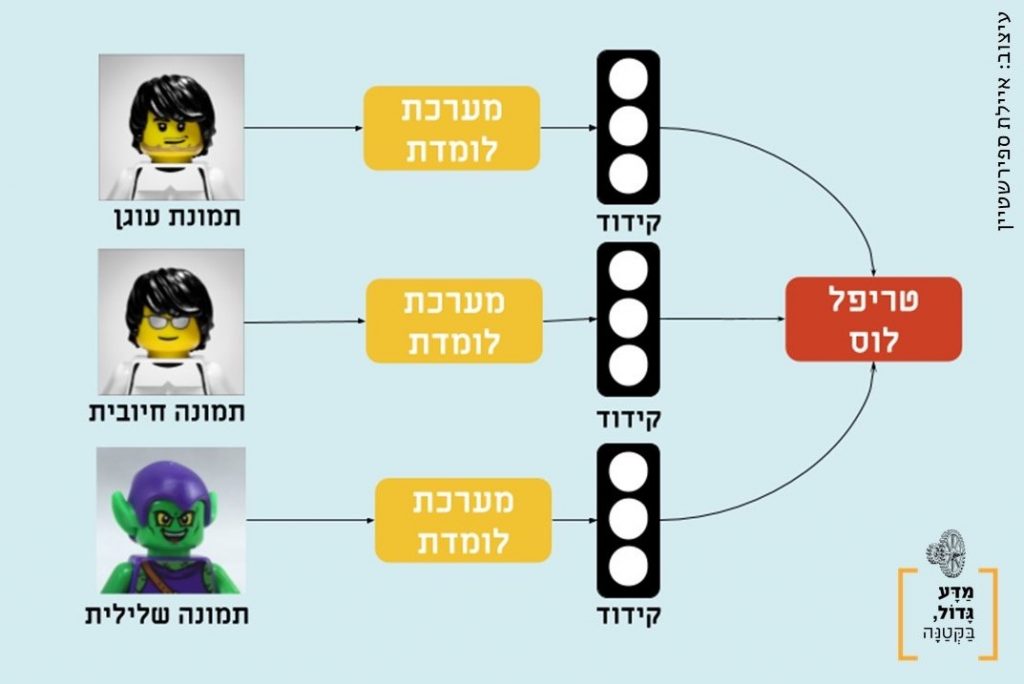
כדי להגדיל את דיוק המערכת לא נסתפק בכך שהנקודה של התמונה נכונה תהייה קרובה יותר לעוגן מהתמונה השגויה, נרצה שהיא תהייה קרובה יותר בפער מהתמונה השגוייה, ולכן נעניש את המערכת גם אם היא צדקה אבל ההבדל במרחקים היה קטן ממרחק מסוים שנקבע מראש.
בחירת השלשות מתבצעת ע"פ המשפט הידוע "קשה באימונים - קל בקרב", מכיוון ששלשות "קלות" - כאלו שהמערכת מצליחה לענות עליהן ברוב המקרים - לא יועילו במיוחד לשיפור המערכת. כדי שהמערכת תשתפר חשוב לבחור שלשות שיאתגרו את המערכת.
לפני שנבחר את השלשות לפיהן אנחנו מלמדים, נסתכל על מקומי הנקודות שהמערכת יוצרת עבור התמונות, ונחפש זוגות של חיוביים קשיים: תמונות של אותו בן אדם שהנקודות שלהן רחוקות ביחס לזוגות אחרים של תמונות המייצגות את אותו בן אדם, או שליליים קשים: זוגות של תמונות המייצגות אנשים שונים שהנקודות שלהן קרובות. כבסיס לשלשות שאליהן נשאל את המערכת.
החוקרים במאמר שמו לב שבחירה בשלשות המורכבות מהזוגות השליליים הכי קשים, יצרה בעיות במערכת וגרמה לה לקרוס, כדי להימנע מבעייה זו הם גילו שאם דואגים שבשלשות הנבחרות העוגן קרוב יותר לנקודה הנכונה מאשר לנקודה הלא נכונה, המערכת מצליחה ללמוד בצורה טובה יותר. הן קראו לשלשות האלה קשות למחצה, מפני שהמערכת ענתה עליהן נכון אבל גבולית, והן נענשות על התשובות האלו רק מעט, ולכן בכל זאת הן לומדות מזה.
אז עכשיו שהבנו איך זה עובד, נענה על השאלה איך אפשר לחמוק ממערכת הזיהוי? אדם שרוצה לחמוק מזיהוי לרוב לא יכול לשלוט בתנאי תאורה, תנוחה ומרחק, אלא רק במראה החיצוני שלו. אבל לפני שאתם ממהרים אל שולחן הניתוחים, חוקרים מאוניברסיטת קרנגי מלון פיתחו משקפיים מצחיקים וצבעוניים שמסוגלים להטעות מערכות לזיהוי פנים מבוססות מערכות לומדות [2]. החוקרים פיתחו אלגוריתם כדי למצוא את הצבעים האופטימליים עבור משקפי ראיה בשביל לחמוק מזיהוי נכון על ידי המכונה.
במקום לשנות את המראה שלנו, אפשר לשנות את התמונות שאליהן משווים. לפני חודש קבוצה של מהנדסי מחשבים מאוניברסיטת שיקגו פרסמה קוד פתוח שמגן על התמונות מפני זיהוי פנים. המערכת מסווה את התמונות מהאינטרנט על ידי שינוי עדין של מאפייני הפנים. תוכלו לקרוא על כך בהרחבה בכתבה שפורסמה לאחרונה במוסף דה מרקר [4]
כיום, חוקרים מנסים לפתח מערכות שיהיו חסינות מול הטעיות כמו אביזרי לבוש, איפור ותסרוקות. אבל עד אז אולי הובס ושואו היו יכולים פשוט להרכיב משקפיים ואז היינו מפסידים סצינת מכות - אבל המעבר בדלת היה פשוט יותר.
קישורים ומקורות:
[1] הובס ושואו VS מערכת זיהויי פנים. הקטע בדקה 02:20
[2] משקפיים שמסוגלות להטעות מערכות לזיהוי פנים מבוססות מערכות לומדות
[3] כתבה על זיהוי פנים באתר של מכון דוידסון
[4] כתבה במוסף דה מרקר על מערכת פוקס (Fawkes) שמגנה על תמונות מפני זיהוי פנים

אלגוריתמאית בתחום ראייה ממוחשבת ורשתות נוירונים. ממנהלי פורום התוכנה Ai-Ml של IsraelClouds, ואמנית. למדה לתואר ראשון במתמטיקה ומדעי המחשב באוניברסיטת בן גוריון ותואר שני במדעי המחשב באוניברסיטה העברית.