הצלחה או כישלון? ביג דאטה יודע
25/07/2018

פרסומת
נניח שאנו מחפשים שיטה להעריך האם סטודנטים יצליחו לסיים את התואר באמצעות בדיקת הישגיהם בקורסים של שני מרצים בלבד. לשם כך, נבקש מהמרצים למצוא את ציוניו של כל סטודנט שלימדו בעבר, ולתת את הערכתם לסיכוי שהסטודנט אכן סיים את התואר. בנוסף, נבדוק מה קרה בפועל, ונבנה מאגר נתונים: למשל, עבור סטודנט מסוים מרצה א' נתן סיכוי של 0.7, מרצה ב' נתנה סיכוי של 0.4, וידוע שהסטודנט נכשל.
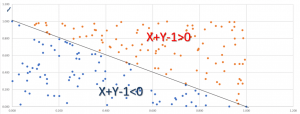
כיצד נשתמש בנתונים? חוקרים בעלי נטייה לסטטיסטיקה ינסו אולי לנתח לעומק את המספרים. אולם, אנשי "ביג דאטה" מנסים לחזות הצלחה עתידית בדרך אחרת, תוך שימוש במידע הרב שמתקבל מנתוני כל הסטודנטים. נדגים את השיטה בדרך גיאומטרית (ציור באתר). ראשית, נצייר את הנתונים במערכת הצירים (מרצה א', מרצה ב'), למשל בדוגמה (0.4, 0.7). לאחר מכן, נצבע את נקודות ההצלחה הידועות באדום ואת נקודות הכישלון הידועות בכחול, וננסה להפריד ביניהן (או לפחות בין רובן) על ידי שרטוט קו הפרדה שיצור חלוקה לאזור של אדומים ולאזור של כחולים. שלב זה נקרא שלב האימון (training).
השלב הבא הוא שלב היישום. כאשר סטודנט חדש יסיים את הקורסים אצל שני המרצים, הם יתנו לנו את חוות דעתם על סיכוייו (זוג מספרים המתאר נקודה). אנו נבחן אם הנקודה נופלת באיזור האדום או באזור הכחול, וכך נוכל לשער אם הסטודנט יצליח או עתיד לפרוש! כך עובדת שיטת החיזוי ב"למידה ממוחשבת". מטרת המשערך היא לבצע ניחוש מושכל בהתאם לנתונים ולניסיון העבר. אם יש הפרדה טובה בין האזורים, הסיכוי שנצליח בחיזוי גדל.
האלגוריתם הבסיסי בנושא, שפותח עוד בשנות השישים נקרא פרספטרון [1]. הוא מנסה לבנות משוואה לינארית פשוטה שתחלק את המרחב לאזורים נפרדים, בדוגמה שלנו: הצלחה וכישלון בלימודי התואר. משערך אפשרי להצלחה בלימודים בדוגמה הוא: 2y+3x-2.5 >0 . בשלב האימון, אם מתגלה נקודה שלא מקיימת את התנאי הלוגי, למשל (0.7,0.4) שבה חזינו הצלחה בלימודים ( כי בהצבה מתקבל 0 <0.4) אבל הסטודנט נכשל, האלגוריתם יעדכן את המקדמים במשוואה. אלגוריתמים מודרניים משתמשים במשערכים מוצלחים יותר, שמציעים הפרדה טובה בין התחומים (ראו מאמר שלנו על גדר ההפרדה [2]). במציאות, האלגוריתמים משתמשים בהרבה מקורות אינפורמציה, ובכמות גדולה של נתונים שנאספו בעבר. "ביג דאטה" - כבר אמרנו?
כיום, יש שפע של שימושים ללמידת מכונה וים של מאמרים בנושא. מה היתרונות והחסרונות? בפרק נהדר בפודקאסט "עושים היסטוריה" של רן לוי [3] מתואר ניסיון של אנשי גוגל ב-2006 לחזות התחלת התפרצות שפעת בארצות הברית. השיטה הייתה לנתח אילו שאילתות אנשים שאלו את מנוע החיפוש של גוגל בזמנים אלו. הצוות לא ידע לבחור אילו שאילתות רלוונטיות, אז הוא נתן למחשב לנתח חמישים מיליון שאילתות. המחשב מצא ארבעים וחמש שאילתות שהפגינו את המתאם הגבוה ביותר להתפרצות שפעת במשך 5 שנים ויצר משערך לחיזוי שפעת. השיטה נוסתה בהצלחה במשך שנתיים, פורסמה ועוררה עניין רב. אולם בהמשך, ב-2013, היא הפסיקה לעבוד. התברר שהשיטה רגישה מאוד לשינויים, ובשנה זו היו אזהרות מוקדמות בתקשורת להתפרצות שפעת, מה שגרם להערכה מוגזמת של המשערך למידת ההתפשטות.
דוגמה זו מציגה את היתרונות והבעייתיות של שימוש בשיטת "למידת מכונה" תוך שימוש ב"ביג דאטה": היא עובדת במקרים רבים, אולם היא מייצרת משערכים מורכבים, שקשה להשתמש בהם לצורך ההבנה של העולם. הרבה משתמשים (בעיקר בחברות הייטק) מתהדרים בשימוש בביג דאטה וכלל לא מתעניינים להבין למה זה עובד. אולם הרבה חוקרים עמלים למצוא הגיון וסדר גם בשימוש בשיטות אילו (data mining).
דוגמה נוספת, יותר טרייה ומשונה: בכתבה שפורסמה בעיתון גלובס, מתוארת מערכת "ביג דאטה" שפותחה באוניברסיטת אריזונה לזיהוי סטודנטים שעומדים לנשור מהלימודים באמצעות מעקב אחריהם [4]. מסתבר שבנוסף לציונים, המערכת עוקבת באמצעות כרטיס חכם איפה הסטודנטים מסתובבים ומה הם קונים. לטענת מנהלת הפרויקט, הפרופסורית סודהה רם, יש חשיבות לעקוב גם אחרי המעגל החברתי וחיי השגרה של סטודנטים כדי להעריך אם הם עומדים לפרוש.
אנו מדמיינים מערכת כזאת באוניברסיטת תל אביב. הפרופסורית לאמנויות פונה לסטודנט ואומרת: "המחשב מעריך שאין לך סיכוי להמשיך לתואר, למרות שהציונים בסדר. הוא אסף עליך אלפי נתונים המצביעים על כך: למשל אכלת במקדונלדס וקנית צ'יפס מוגדל, צפית פעמיים בסרט "הנוקמים", אתה מבלה פחות מדי זמן על הדשא בפקולטה…" - נשמע הזוי, אבל זה המידע שהמחשב יכול לספק, בזמן שהוא בונה את משוואת המשערך. למרות המוזרות, ייתכן שהמערכת תהיה דווקא שימושית לסטודנטים וליועצים כדי להתריע על בעיות ולעזור לסטודנטים לסיים בהצלחה את לימודיהם.
אחד הדברים המוצלחים ב"למידת מכונה" תוך שימוש ב"ביג דאטה" הוא הנגישות לציבור. למרות ששיטות אילו משתמשות באלגוריתמים מתמטיים מורכבים למדי, אלגוריתמים אילו מוטמעים בתוך ספריות המאפשרות להשתמש בהן די בקלות, בלי צורך ללמוד קורסים כבדים בסטטיסטיקה, למשל [5].
כל מאגר שמכיל מידע רב ניתן לניתוח בכלי "ביג דאטה" כדי להפיק תובנות חדשות. למשל, רשות החדשנות עובדת על פיתוח והנגשת מאגר מידע בנושא מזון, שמטרתו לאפשר מדידת "ביג דאטה" לאורך שרשרת הייצור של מזון במטרה לשפר את יעילות הייצור ולהגביר את השקיפות של ערכי המזון עבור הצרכנים. למשל, תוכלו לדעת בדיוק מה איכות התירס שממנו הוכנה הבמבה שלכם.
מקורות וקריאה נוספת:

דוקטור לפיזיקה, בוגר הטכניון בחיפה. התמחה בפיזיקה של חלקיקים יסודיים, פיזיקה של מצב מוצק ואופטיקה. כיום, עוסק בעיבוד תמונה, עיבוד אותות ובלמידת מכונה. לשעבר המנהל המקצועי של עמותת "מדע גדול, בקטנה".